
What Kind of Dog Is a Watchdog?
In complex systems such as automotive electronics, industrial control, aerospace, and intelligent devices, watchdog mechanisms play a unique role. They are not involved in main business logic, yet they determine whether a system can safely and stably recover from abnormal conditions, forming a critical foundation for overall reliability and safety. For engineers, a watchdog is not an optional feature; it is a baseline capability of system-level design. Without understanding it, one cannot truly comprehend how a system maintains long-term reliable operation in the real world.
This article explains the working principles, architectural patterns, role evolution, and reliability relevance of watchdog mechanisms from an engineering perspective.

Why a Watchdog Is Absolutely Necessary
Any computing system will inevitably encounter unpredictable exceptions and uncertainty. Even if the software contains no logic errors, failures in peripherals, data corruption, electromagnetic interference, runtime resource exhaustion, or race conditions may cause the system to freeze or stop responding.
Engineers often focus heavily on functional implementation, but it is nearly impossible to verify every abnormal path. The purpose of the watchdog is not to prevent all faults, but to ensure that once a fault occurs, the system can automatically recover. This philosophy aligns with the fault-tolerant principles used in avionics, nuclear control, and other high-reliability sectors:
Failures are inevitable, but recovery must be reliable.
Thus, the watchdog is the final safety net and the last line of defense ensuring a healthy system.
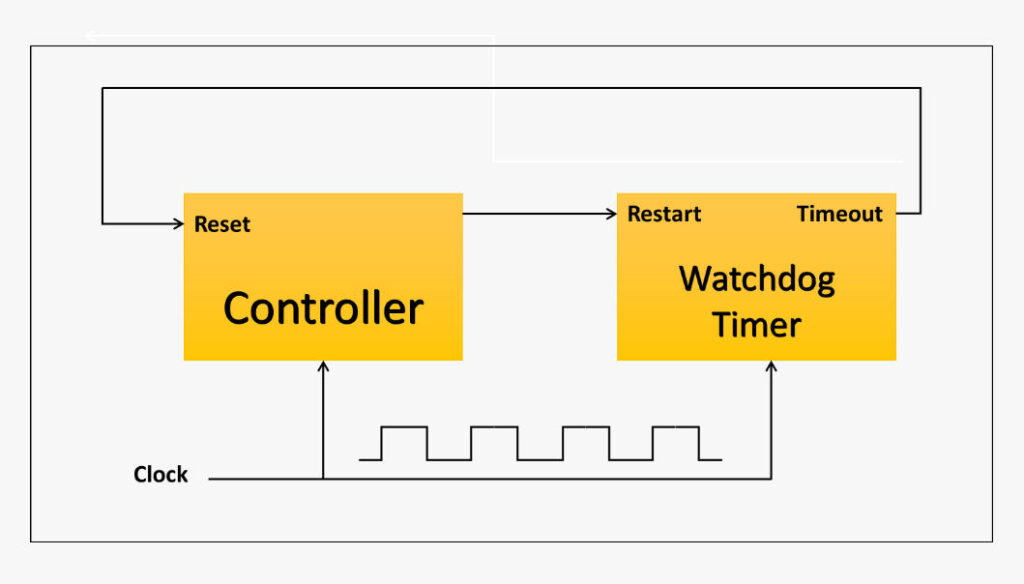
System Positioning of the Watchdog: An Independent Supervisor
A watchdog is an independent supervisory mechanism detached from business logic. Its value lies in its independence. A system cannot verify by itself whether it is still healthy, so the watchdog uses external timing to validate the system’s liveness through periodic survival signals.
In traditional embedded devices, watchdogs rely primarily on hardware counters. In modern systems, however, watchdog concepts extend across multiple layers. Operating system kernels, virtualization layers, and cloud-native container schedulers all incorporate health checks, timeout recovery, and automatic restart mechanisms inspired by watchdog principles. The watchdog has evolved from a hardware feature to a system-level design philosophy, supporting autonomy and self-healing across diverse architectures.
Multi-Level Implementation of Watchdog Mechanisms
In real engineering practice, watchdog mechanisms rarely exist as a single module. They are often layered and mutually reinforcing.
Hardware watchdog
A hardware timer inside the chip operates independently of software, unaffected by software failures. It provides the highest priority and strongest recovery capability, capable of forcing resets when the system becomes completely unresponsive. Its reliability stems from independence and non-maskability.
Software watchdog
Implemented by the OS, scheduler, or application framework, it supervises higher-level failures such as task timeouts, process deadlocks, or interface response issues. It is suitable for complex systems, particularly those with multitasking environments.
Distributed watchdog
In cloud, automotive domain controllers, and distributed industrial systems, cross-node and cross-container supervision mechanisms—such as heartbeats, health probes, or master-standby switchover logic—perform watchdog-like monitoring at a higher scale. The concept remains the same, but the monitored object expands from a single process to an entire service or cluster.
Together, these layers form a hierarchical recovery chain. Upper-layer watchdogs provide fine-grained detection, while deeper layers provide ultimate recovery when any layer fails.
The Real Difficulty: Feeding the Watchdog Is Not Just “Calling a Function”
The design of the feed mechanism determines whether the watchdog is effective. In practice, how the watchdog is fed directly affects system resilience.
A valid watchdog feed must:
- Be tied to the real execution path of critical tasks
- Reflect true system health, not merely show that a loop is still running
- Occur within a proper time window to prevent accidental feeding during system freeze
- Avoid being triggered during abnormal states, preventing fault masking
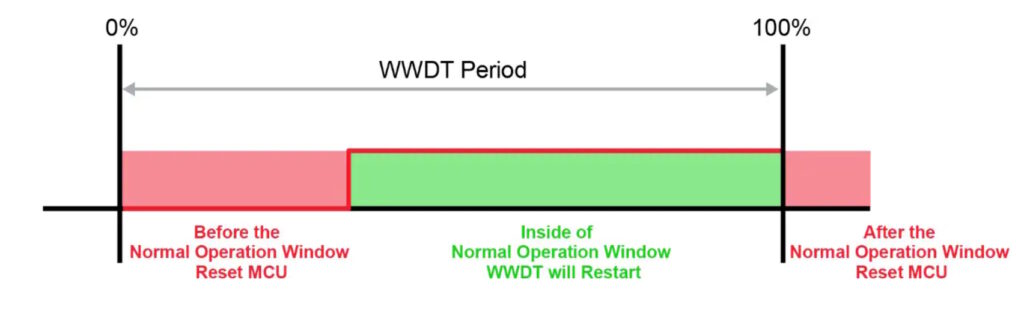
In safety-critical systems, feed conditions are deliberately designed based on multiple combined events. For example, feeding may require the successful completion of multiple tasks or a specific system state combination. This ensures that feeding only happens when the system is truly healthy.
This is known as a windowed watchdog strategy, a crucial method to ensure high reliability in advanced systems.
Deep Integration of Watchdogs in Modern Architectures
With increasing system complexity, the watchdog has evolved from a chip-level defense mechanism to a core module enabling system-level self-healing.
Real-time operating systems
Thread-level watchdogs can monitor scheduling cycles, priority inversion, and timing anomalies, coordinating with hardware watchdogs to create multi-layered fault tolerance.
Automotive electronics
In ISO 26262-compliant designs, watchdogs are mandatory. Many automotive safety chips integrate hardware watchdogs, with software and hardware watchdogs required to cross-monitor each other to achieve ASIL-grade fault coverage.
Smart devices
Mobile phones, routers, and IoT devices use software watchdogs to detect freezes, deadlocks, and memory leaks, enabling automated recovery to reduce user-visible issues.
Distributed systems
Heartbeats, liveness probes, and automated restart policies in containers and microservices follow the same principle, simply applied at the scale of distributed nodes.
Watchdogs have become foundational self-healing infrastructure across modern computing systems.
Beyond Resetting: The Watchdog’s Role in Reliability Engineering
Many engineers think watchdogs simply trigger system resets. In mature reliability frameworks, watchdogs perform far more advanced functions.
Fault data capture
Before resetting, the system may record registers, stack information, logs, or memory snapshots for post-mortem analysis.
Tiered recovery
Depending on fault severity, the system may restart only a module, a process, a subsystem, or the entire system.
Health trend analysis
Frequent watchdog triggers indicate underlying issues such as resource leakage, power noise, aging, or environmental interference.
Safety protection
In safety-critical systems, watchdogs can trigger safe states or fallback modes, such as automotive emergency protection or industrial equipment shutdown.
Thus, watchdogs form an essential part of the complete reliability and fault-management loop.
The Most Commonly Overlooked Issue: The Quality of the Watchdog Design Itself
Failed watchdog implementations are common causes of reliability problems. Common mistakes include:
- Feeding from the wrong logic path
- Incorrect window configuration leading to false resets or missed faults
- Software watchdogs depending on the same scheduler that may fail
- Not differentiating initialization vs runtime states
- No strategy for post-reset diagnosis and recovery
- Lack of periodic testing of hardware watchdog functionality
In safety-critical domains, the watchdog itself must undergo rigorous verification to prove controllability and fault-coverage capability.
A Watchdog Represents an Engineering Philosophy: Systems Must Be Self-Healing
As systems grow more complex, we cannot expect software to be perfect or environments to be stable. System-level self-healing will be a core direction of future reliability design, and the watchdog is the most fundamental, mature, and trustworthy implementation of this philosophy.
The watchdog reminds engineers that software is not inherently reliable, systems must be able to recover, and reliability is achieved not by avoiding all failures, but by surviving them.
This understated mechanism is what enables complex systems to run safely, predictably, and stably over the long term.